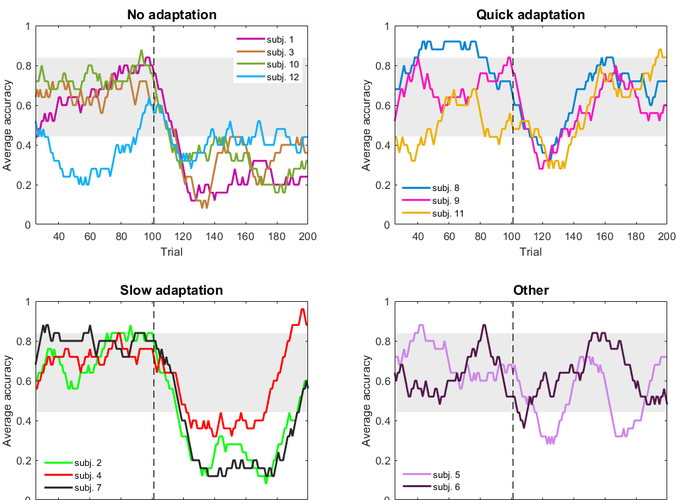
The study of uncertainty in reinforcement learning (RL) has received an increased interest in the last decade. Two prominent types of uncertainty that have been studied extensively are expected and unexpected uncertainty (Yu and Dayan, 2003; Bland and Schaefer, 2012). Expected uncertainty refers to a known unreliability in the environment due, for example, to rewards being generated from a stable probability distribution; whereas unexpected uncertainty reflects a fundamental change in the environment that is not expected by the agent, such as a non-signalled change in the rules of the task. Several studies have suggested that humans are capable of learning under these two types of uncertainty (Behrens et al., 2007; Nassar et al., 2010; Wilson and Niv, 2011). However, these studies have concentrated mainly on reward uncertainty.
Here, we investigated how people learn under expected and unexpected uncertainty when the source of uncertainty is the state in comparison with the case of reward uncertainty. In the case of state uncertainty, we designed a novel task where the stimuli were noisy, so that participants could not unambiguously identify the true state, and tested whether participants could learn the correct rules under this state uncertainty condition, and whether they could detect a non-signalled reversal of stimulus-response contingencies, despite the presence of state uncertainty. In the case of reward uncertainty, we used a similar task but with stimuli being unambiguous and rewards being generated randomly with the same uncertainty level used in the state uncertainty task. The inclusion of both state and reward uncertainty conditions allowed us to investigate the differences in learning performance between the two uncertainty conditions. Finally, to find out the computational mechanisms used by participants to learn under different conditions, we compared their behaviour to three types of computational learning mechanisms: a simple RL, a Bayesian RL and a sampling-based learning model.
References
Behrens, T. E., Woolrich, M. W., Walton, M. E., and Rushworth, M. F. (2007). Learning the value of information in an uncertain world. Nature neuroscience, 10, 1214–1221.
Bland, A. R. and Schaefer, A. (2012). Different varieties of uncertainty in human decision-making. Frontiers in neuroscience, 6.
Nassar, M. R., Wilson, R. C., Heasly, B., and Gold, J. I. (2010). An approximately bayesian delta-rule model explains the dynamics of belief updating in a changing environment. The Journal of Neuroscience, 30, 464 12366–12378.
Wilson, R. C. and Niv, Y. (2011). Inferring relevance in a changing world. Frontiers in human neuroscience, 5, 189.
Yu, A., and Dayan, P. (2003). Expected and unexpected uncertainty: ACh and NE in the neocortex. In Advances in neural information processing systems 15 (eds. S.T.S. Becker, & K. Obermayer) (pp. 157–164). Cambridge, MA: MIT press.