Working memory-based reinforcement learning (RL) models (O’Reilly and Frank, 2006; Zilli and Hasselmo, 2008; Todd et al., 2009) are often slow to learn and require setting the learning parameters carefully in order to reasonably expect convergence to an optimal policy. In particular, it is crucial to allow the models to explore enough but not excessively (i.e., balancing the trade-off between exploration and exploitation). Solving the exploration-exploitation trade-off is especially critical in these models, as the addition of a working memory to the agent results in a sizeable state-action policy space.
Thompson sampling has received increasing interest in recent years as a method for balancing exploration and exploitation in bandit problems (May et al., 2012). It is self-tuning and automatically anneals exploration-exploitation in response to the level of information in the value estimates. The general idea behind Thompson sampling is to choose an action according to its probability of having the highest value. As such, it requires the estimation of posterior distributions of action values instead of simply action values. Thus a Bayesian approach to RL is required.
Despite its elegance, the Bayesian approach has only been used occasionally in modern RL. Among the few model-free Bayesian RL models that have been proposed in the literature are the SARSA variant of the Kalman temporal difference model (KTD-SARSA) and its extended version (XKTD-SARSA), both of which use online value function approximation along with Kalman filtering to estimate the state-action value function of a given policy (Geist and Pietquin, 2010). A related algorithm is the SARSA-based Gaussian process temporal difference (Engel et al., 2005), which can be seen as a special case of the KTD-SARSA model in stationary environments. These models consider state-action values to be random processes and compute their posterior distribution given the observed rewards and transitions.
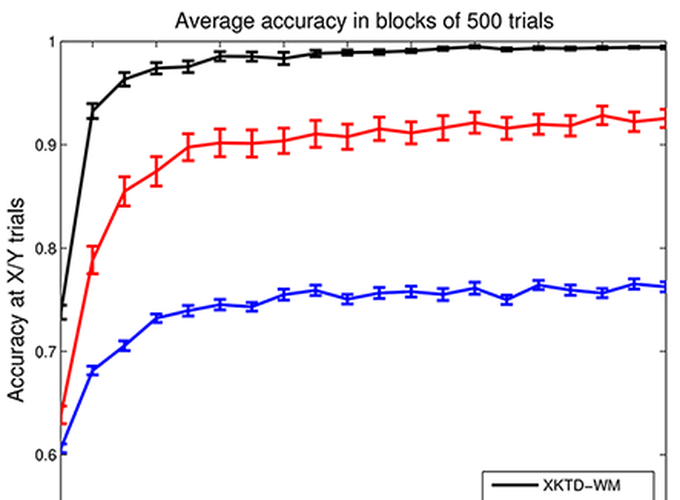
In this project, we use a modified version of the XKTD-SARSA model that does not use value function approximation, and show that it has a similar form of updates to the standard SARSA(lambda), but with time- and state-dependent step-sizes that are governed by the learned properties of the system instead of arbitrary learning rates and eligibility traces. We then show how to implement XKTD-SARSA for a non-Markovian model incorporating a working memory module, following Todd et al.’s (2009) approach. Finally, we compare the performance of the Bayesian working memory-based RL with the non-Bayesian counterpart on the 12-XY and 12-AB-XY–two simplified versions of the 12-AX task (Frank et al., 2001).
References
Engel, Y., Mannor, S., and Meir, R. (2005). Reinforcement learning with Gaussian processes. Proceedings of the 22nd international conference on Machine learning - ICML ‘05, pages 201-208.
Frank, M. J., Loughry, B., and O’Reilly, R. C. (2001). Interactions between the frontal cortex and basal ganglia in working memory: A computational model. Cognitive, Affective, & Behavioral Neuroscience, 1(2):137-160.
Geist, M. and Pietquin, O. (2010). Kalman temporal differences. Journal of Artificial Intelligence Research, 39:483-532.
May, B. C., Korda, N., Lee, A., and Leslie, D. S. (2012). Optimistic Bayesian sampling in contextual-bandit problems. The Journal of Machine Learning Research, 13:2069-2106.
O’Reilly, R. C. and Frank, M. J. (2006). Making working memory work: A computational model of learning in the prefrontal cortex and basal ganglia. Neural Computation, 18(2):283-328.
Todd, M. T., Niv, Y., and Cohen, J. D. (2009). Learning to use working memory in partially observable environments through dopaminergic reinforcement. In Advances in neural information processing systems, pages 1689-1696.
Zilli, E. A. and Hasselmo, M. E. (2008). Modeling the role of working memory and episodic memory in behavioral tasks. Hippocampus, 18(2):193-209.